Multiple Flow Convergence
Given multiple bbr flows competing at the same bottleneck, all of the flows should sync. BBR has a mechanism to drain the queue and check for a lowest round trip time after some amount of seconds since the last time the round trip time changed. With multiple flows, they all should see the change in round trip time at the same time, so they should begin to drain the queue at the same time.
The goodput (throughput seen by the receiver) should looks something like this result published by the BBR team in this paper:

And our results, which look roughly similar:

See below for the configuration details and analysis
Raspberry Pi
Each client (churro 1 - 4) and server (tarta 1 - 4) is set to use BBR as their congest algorithm. This can be done with the commands:
sudo sysctl net.core.default_qdisc=fq;
sudo sysctl net.ipv4.tcp_congestion_control={cc};
sudo sysctl net.ipv4.tcp_congestion_control;
Iperf3
We create four iperf3 flows from the churro subnet to the tarta subnet. The bulk sender (the iperf3 client) connects from churro1 to tarta1 for each pair.
Server:
iperf3 -s
Client on each churro:
iperf3 -c tarta<n> -t 120
Simulating a 80mbps Link
Note: our raspberry pi testbed is running a slightly newer version of bbr than the one used to generate the graphs in this paper.
TC: Traffic Control
TC is a tool that allows us to control the traffic leaving the interface towards the tarta subnet. In TC,
there are a number of different queueing disciplines (qdisc) that can be used to control this traffic. We looked
at 4 different qdiscs to recreate the BBR results above.
Token bucket filters with netem delay
The token bucket filter (tbf) for tc creates a bucket of tokens that generate at some rate. Packets that arrive can only be sent using a token. This allows us to effectively control the rate of transmission for the interface to the desired 80mbps.
To create the 10ms delay, we used Netem, a network emulator that can be used to add delay and simulate loss on an otherwise perfect wired connection.
The setup for these two qdisc can be done as follows:
# delete old rules
sudo tc qdisc del dev enp3s0 root
# Add the netem delay
sudo tc qdisc add dev enp3s0 root handle 1:0 netem delay 10ms
# Add the tbf as a child to the netem
sudo tc qdisc add dev enp3s0 parent 1:1 handle 10: tbf rate 80mbit buffer 1mbit limit 1000mbit
tc -s qdisc ls dev enp3s0
And, here are the results:
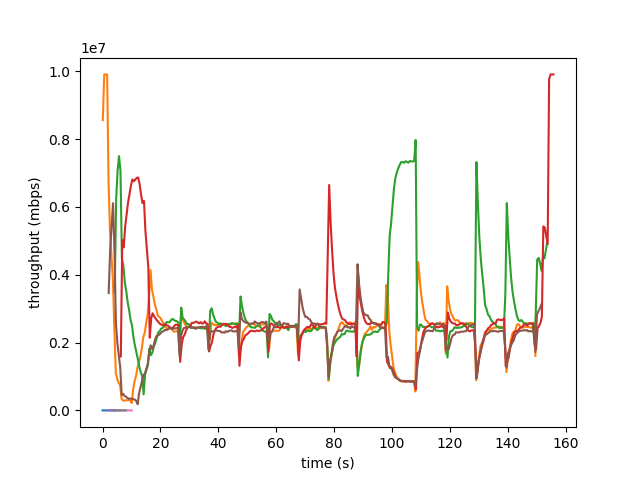
Unfortunately, there are ‘spikes’ in the graph after every phase where BBR is draining the queue. This could be because we are using a slightly different version of BBR than the original paper used, but we believe the real cause is the token bucket filter.
Because the token bucket filter fills up tokens at a constant rate and BBR underutilizes the link during the draining phase, the token bucket filter will generate a pool of tokens. So, when the first flow leaves the draining phase, it will be able to send all of its packets through this token bucket immediately as there is a surplus of tokens. This could be the cause of the spikes.
That being said, the convergence to a fair throughput is promising. But, we continued to explore other queue disciplines to remove these bursts.
Netem with Rate Control
After reading the netem documentation, it looks like netem natively supports rate control now. So, we tried to do a similar test with netem to see if this reduced the burst issues of the token bucket filter.
This was the setup:
sudo tc qdisc del dev enp3s0 root
sudo tc qdisc add dev enp3s0 root handle 1:0 netem rate 80mbit delay 10ms
tc -s qdisc ls dev enp3s0
And this was the result:
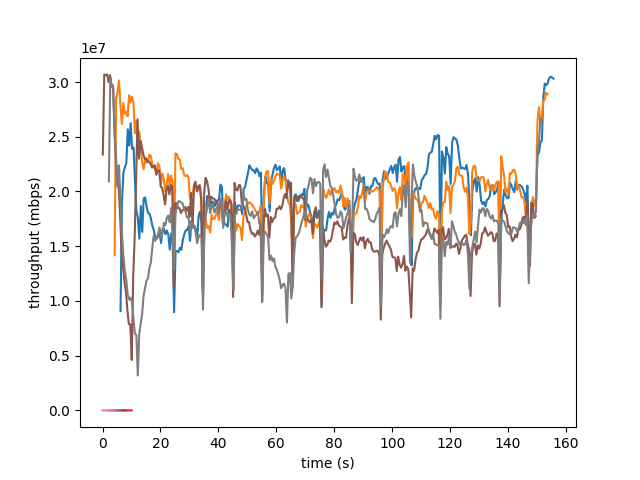
While the flows did seem to sync, the throughput was all over the place. Additionally, despite the rate being capped at 80mbps and the first flow starting 2 seconds before the next flow, the maximum observed throughput is only around 30mbps. I think this is because netem is not provided consistent rate limiting or latency. the man page does provide this quote:
The main known limitation of Netem are related to timer granularity, since Linux is not a real-time operating system.
which may indicate that the rate features are not completely stable (at least not at the precision we need). As this is a relatively new feature in netem, there is not much documentation on why we may be having these results.
TBF with peak rate limits
As ‘burstiness’ is a common problem with token bucket filters, there are ways built in to mitigate these issues. Specifically, you can set a peak rate for the token bucket. This should limit the maximum rate at which tokens can be used from the bucket. So, if this is set to or close to the bucket-filling rate, then this should eliminate the burst.
Our setup:
sudo tc qdisc del dev enp3s0 root
sudo tc qdisc add dev enp3s0 root handle 1:0 netem delay 10ms
sudo tc qdisc add dev enp3s0 parent 1:1 handle 10: tbf rate 80mbit buffer 1mbit limit 1000mbit peakrate 81mbit mtu 1500
tc -s qdisc ls dev enp3s0
Note: we tried the mtu at a number of sizes larger than and smaller than the mtu of our target interface (1500).
Our Results:
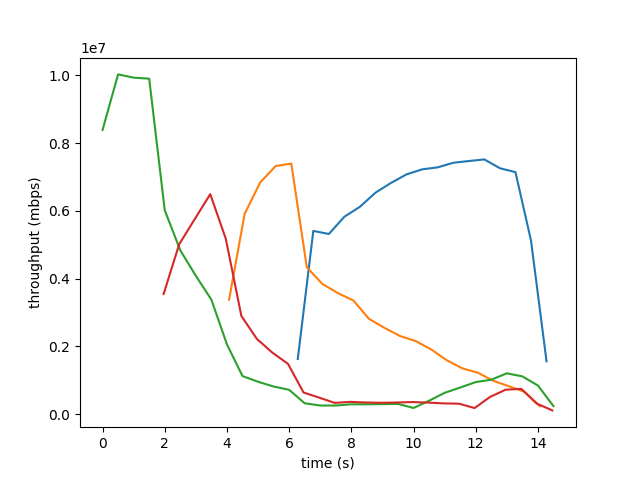
Aborted early
This trial resulted in zero throughput after the bucket was drained. We are still unsure why. We will continue exploring this.
Cake
Cake is a more sophisticated queuing discipline for shaping traffic. While the results were initially promising (the graphs looked good), we believed that Cake was doing too much to shape the traffic, such as limiting the rate per flow (even with the settings off).
As this would make the results of our experiments harder to reason about, and thus effectively worthless for validating our test bed, we decided to not pursue cake further.
Final Solution: Two Token Buckets
With a single token bucket, there needs to be some accumulation of tokens or the total rate which never reach the desired rate. To quote the man pages: > In general, larger shaping rates require a larger buffer. For 10mbit/s on Intel, you need at least 10kbyte buffer if you want to reach your configured rate!
The idea behind the peak rate setting is to add a second token bucket with a much smaller buffer. This will catch the burst from the token bucket and ensure that the ‘burst’ from the first token bucket is much smaller. Unfortunately, I was not able to get the peak rate setting on the tbf to work correcetly.
The solution we found was to manually create a second token bucket, shown below:
Note: this simulation minimizes drops by setting the limit / queue size to be very large for each queuing discipline
sudo tc qdisc del dev enp3s0 root
sudo tc qdisc add dev enp3s0 root handle 1:0 netem delay 10ms limit 1000
sudo tc qdisc add dev enp3s0 parent 1:1 handle 10: tbf rate 80mbit buffer 1mbit limit 1000mbit
# Add a second token bucket with a much smaller buffer / burst size
sudo tc qdisc add dev enp3s0 parent 10:1 handle 100: tbf rate 80mbit burst .05mbit limit 1000mbit
tc -s qdisc ls dev enp3s0
This produces much smaller bursts in the graph, as shown here:
Note: we use four flows at 80 mbps instead of 5 flows at 100 mbps. This is because we have 8 machines, and thus can only test multiples of four flows with identical conditions.
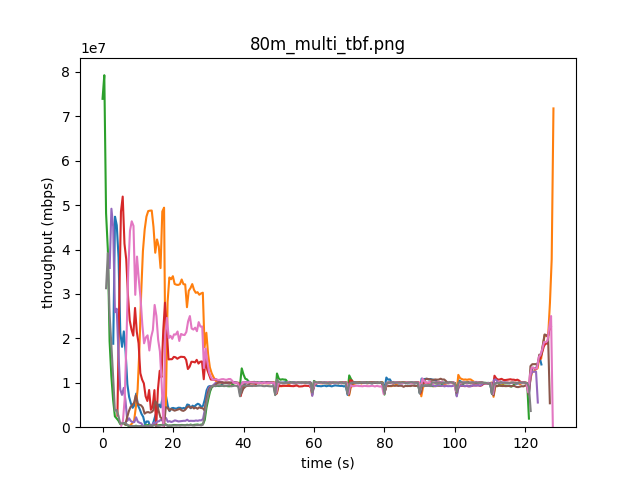
This behavior very closely matches the behavior produced by the google bbr team, albeit with very small bursts after each draining phase.
With more flows (16) the behavior continues to be quite reasonable.
